القائمة
حل مشكلة الهلوسة: قوة RAG والنماذج اللغوية المحلية
تم النشر في November 28, 2025
حل مشكلة الهلوسة: قوة RAG والنماذج اللغوية المحلية
كلما أصبحت أنظمة الذكاء الاصطناعي أكثر تطورًا، بقيت نقطة حساسة تُبطئ تبنّيها داخل المؤسسات: الهلوسة. وهي تحدث عندما تنتج النماذج اللغوية الكبيرة إجابات تبدو واثقة جدًا، لكنها في الحقيقة خاطئة أو حتى مختلقة بالكامل.
في قطاعات مثل القانون والتمويل والرعاية الصحية والجهات الحكومية، قد يؤدي خطأ واحد فقط إلى تبعات قانونية أو مالية أو حتى ضرر كبير في السمعة. في هذه البيئات، الدقة ليست خيارًا—بل ضرورة.
هنا يأتي دور Retrieval-Augmented Generation (RAG) وتشغيل النماذج اللغوية محليًا ليغيّرا المعادلة من الأساس.
سيادة البيانات: إبقاء أهم شيء تحت السيطرة
أحد أهم مبادئ الذكاء الاصطناعي في المؤسسات هو سيادة البيانات.
يجب أن تعرف المؤسسات بشكل واضح:
- أين يتم تخزين البيانات
- من يمكنه الوصول إليها
- كيف تتم معالجتها
عند تشغيل أنظمة الذكاء الاصطناعي داخل الشركة (On-Premise) أو ضمن بيئة سحابية خاصة، يتم التخلص من خطر إرسال البيانات الحساسة إلى خوادم خارجية. كما تضمن النماذج المحلية أن المستندات الخاصة، والسياسات الداخلية، والسجلات السرّية لا تخرج أبدًا عن البنية التحتية التي تتحكم بها المؤسسة.
وهذا الأسلوب مهم جدًا خصوصًا للقطاعات الخاضعة للرقابة، والتي يجب أن تلتزم بقوانين صارمة لحماية البيانات وسياسات حوكمة داخلية دقيقة.
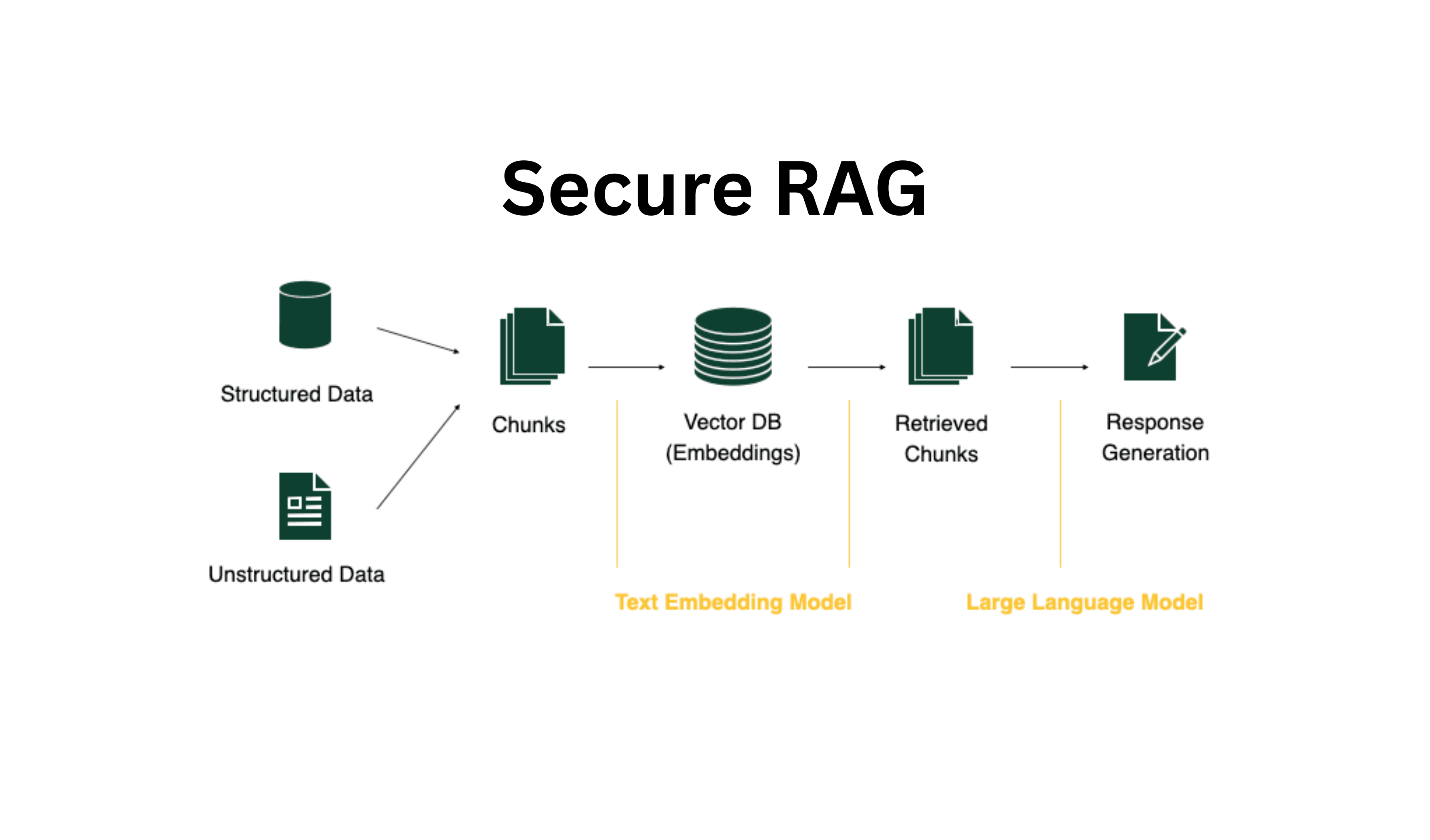
بنية RAG: ربط الذكاء الاصطناعي بالواقع
تعالج Retrieval-Augmented Generation مشكلة الهلوسة من جذورها.
بدل الاعتماد فقط على “المعرفة الداخلية” الموجودة داخل النموذج، تقوم أنظمة RAG بـ:
- جلب المعلومات المطلوبة من مستندات داخلية موثوقة
- إدخال هذه المعلومات مباشرة ضمن سياق النموذج
- إنتاج الإجابة بالاعتماد فقط على المصادر التي تم استرجاعها
والنتيجة هي مخرجات ذكاء اصطناعي مرتبطة ببيانات حقيقية ويمكن التحقق منها.
وإذا لم تكن الإجابة موجودة في قاعدة المعرفة، فالنظام ببساطة لا يخترعها.
هذه البنية تحوّل النماذج اللغوية الكبيرة من أدوات لكتابة نصوص “إبداعية” إلى موظفين معرفيين موثوقين داخل المؤسسة.
تحقق مزدوج: ثق… لكن تأكد
في AIME نذهب خطوة أبعد من ذلك عبر التحقق مزدوج الطبقات.
الفكرة هنا بسيطة لكنها فعّالة:
- نموذج أساسي ينتج الإجابة باستخدام RAG
- نموذج ثانٍ يقوم بالتحقق من النتيجة بشكل مستقل
- يتم رصد أي تناقض، أو ادعاء غير مدعوم، أو نقص في المراجع تلقائيًا
هذا الأسلوب يرفع مستوى الموثوقية بشكل كبير، ويقلل جدًا احتمال وصول معلومات خاطئة إلى المستخدم النهائي.
والنتيجة نظام لا يتصرف كروبوت دردشة عادي—بل أقرب إلى محلل منضبط ودقيق.
الذكاء الاصطناعي الآمن ليس خيارًا إضافيًا
الأمان لا يجب أن يكون “إضافة لاحقة” عند تصميم أنظمة الذكاء الاصطناعي.
عندما تجمع بين:
- مصادر بيانات محلية
- بيئات تشغيل معزولة
- RAG لربط الإجابات بالمصادر
- تحقق متعدد النماذج
يمكن للشركات الاستفادة من قوة النماذج اللغوية الكبيرة بثقة، دون التضحية بخصوصية البيانات أو دقة المعلومات.
في AIME نبني منظومات ذكاء اصطناعي يكون فيها الأمان والدقة والثقة أساسًا ثابتًا—not مجرد ميزات إضافية. وهذا يمكّن المؤسسات من تبنّي الذكاء الاصطناعي على نطاق واسع مع الالتزام بأعلى معايير الأمان والامتثال.